
Your Engineers Should Be Building, Not Babysitting
Engineering teams lose too much product time to on-call supervision, triage loops, repeated regressions, and work that agents can prepare in seconds.
Read articlePractical writing on production debugging, incident remediation, observability, AI-assisted fixes, and the engineering workflows behind self-healing software.
Field notes for leaders and engineers building calmer, faster production remediation loops.
Use these as durable references for engineering leaders, SREs, and teams evaluating automated remediation.
Engineering teams lose too much product time to on-call supervision, triage loops, repeated regressions, and work that agents can prepare in seconds.
Read articleFor AI-assisted remediation, the most useful operational metric may be how quickly a production signal becomes an evidence-backed pull request ready for review.
Read articleAI-generated production fixes become safer when the workflow thinks about reversibility, blast radius, and review evidence before a patch is merged.
Read article
Production bugs get more expensive as context decays, support load compounds, releases freeze, and the fix becomes harder to review.
Read article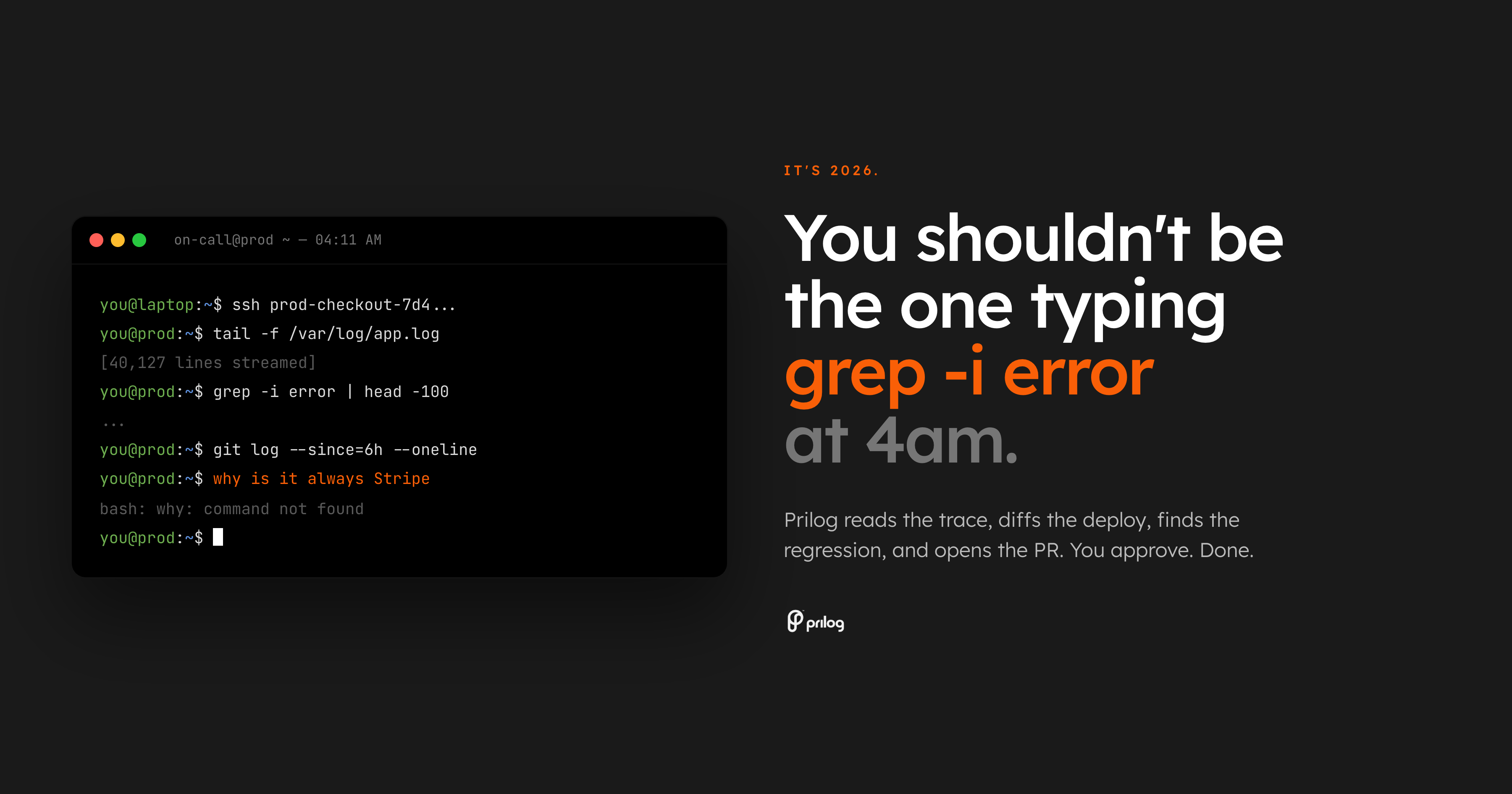
On-call work should start with a prepared incident brief, not a tired engineer manually stitching logs, traces, deploys, and code ownership together.
Read articleA practical model for using AI to draft production fixes while keeping evidence, review, tests, and ownership in the hands of engineers.
Read articleA practical workflow for moving from noisy production alerts to code-level fixes that engineers can review, merge, and trust.
Read articleObservability tells teams what failed; code context explains where to fix it. Here is how to connect logs, traces, ownership, and pull requests.
Read article